1、Tesseract
一款由HP实验室开发由Google维护的开源OCR(光学字符识别)引擎
语法:
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile…]
imagename为目标图片文件名,需加格式后缀;
outputbase是转换结果文件名;
lang是语言名称(在Tesseract-OCR中tessdata文件夹可看到以eng开头的语言文件eng.traineddata),如不标-l eng则默认为eng。
例:tesseract test.png output_1 –l eng
字库
https://github.com/tesseract-ocr/tessdata/find/master
下载chi\_sim.traindata字库。要有这个才能识别中文。下好后,放到Tesseract-OCR项目的tessdata文件夹里面。
tesseract test.jpg result -l chi_sim
但是还是有点不够准确,那么我们有没有什么办法能提高tesseract识别字符准确率呢?
接下来,我们将使用配套训练工具jTessBoxEditor来训练样本,来提高我们的准确率!
大体流程为:安装jTessBoxEditor -> 获取样本文件 -> Merge样本文件 –> 生成BOX文件 -> 定义字符配置文件 -> 字符矫正 -> 执行批处理文件 -> 将生成的traineddata放入tessdata中
https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
参考
http://blog.sina.com.cn/s/blog_660e521d0102uyaq.html
获取样本文件
1、将图片转换成tif格式,用于后面生成box文件。可以通过画图,然后另存为tif即可。
更改图片名字,这个是有要求的=。=
tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言 fontname是字体
比如我们要训练自定义字库 mjorcen字体名normal
那么我们把图片文件重命名 mjorcen.normal.exp0.jpg在转tif。2、使用jTessBoxEditor
点击train.bat---->tool----->Merga TIFF----->选择图片----->保存为---名字.语言.exp0,在修改另存为.jpg

Merge样本文件
生成BOX文件
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 -l eng batch.nochop makebox

字符矫正
打开.tif文件,逐个矫正

执行批处理文件
生成.tr文件
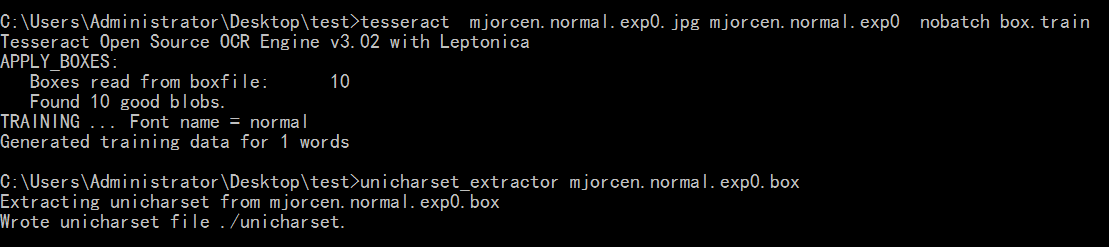
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 nobatch box.train
生成unicharset文件
unicharset_extractor mjorcen.normal.exp0.box
定义字符配置文件
新建一个font_properties文件
里面内容写入
normal 0 0 0 0 0 表示默认普通字体
echo font 0 0 0 0 0 >font_properties
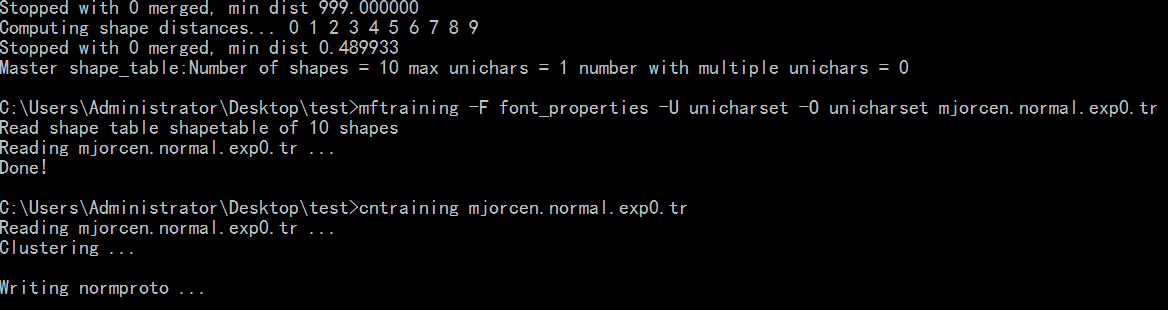
shapeclustering -F font_properties -U unicharset mjorcen.normal.exp0.tr
mftraining -F font_properties -U unicharset -O unicharset mjorcen.normal.exp0.tr
cntraining mjorcen.normal.exp0.tr
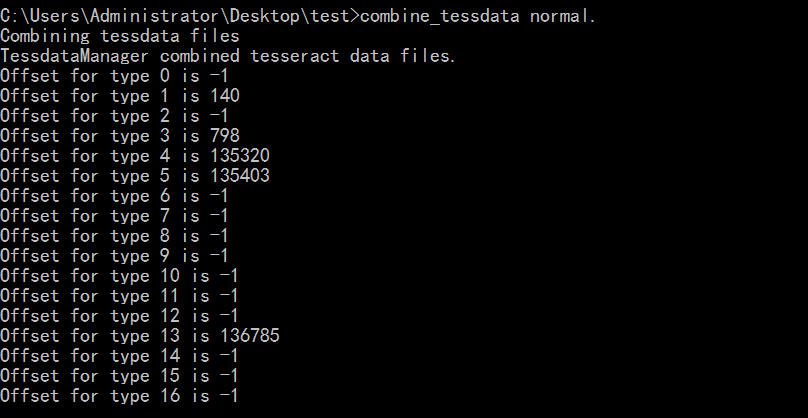
- 把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上normal.

- 执行combine_tessdata normal.
将生成的.traineddata文件放入D:\Tesseract-OCR\tessdata中
测试
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 -l normal