Scrapy-Redis分布式策略:
假设有四台电脑:Windows 10、Mac OS X、Ubuntu 16.04、CentOS 7.2,任意一台电脑都可以作为 Master端 或 Slaver端,比如:
Master端(核心服务器) :使用 Windows 10,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储Slaver端(爬虫程序执行端) :使用 Mac OS X 、Ubuntu 16.04、CentOS 7.2,负责执行爬虫程序,运行过程中提交新的Request给Master
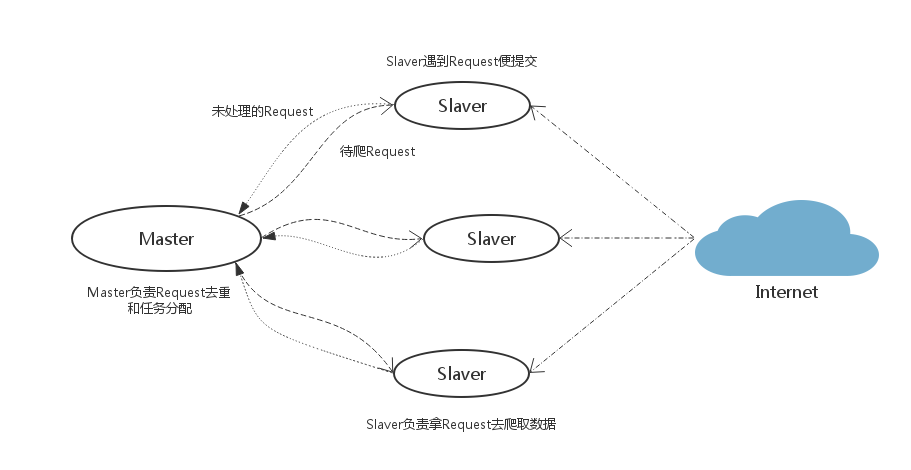
首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
一、安装Redis
安装Redis:http://redis.io/download
安装完成后,拷贝一份Redis安装目录下的redis.conf到任意目录,建议保存到:/etc/redis/redis.conf(Windows系统可以无需变动)
二、修改配置文件 redis.conf
#是否作为守护进程运行
daemonize no
#Redis 默认监听端口
port 6379
#客户端闲置多少秒后,断开连接
timeout 300
#日志显示级别
loglevel verbose
#指定日志输出的文件名,也可指定到标准输出端口
logfile redis.log
#设置数据库的数量,默认最大是16,默认连接的数据库是0,可以通过select N 来连接不同的数据库
databases 32
#Dump持久化策略
#当有一条Keys 数据被改变是,900 秒刷新到disk 一次
#save 900 1
#当有10 条Keys 数据被改变时,300 秒刷新到disk 一次
save 300 100
#当有1w 条keys 数据被改变时,60 秒刷新到disk 一次
save 6000 10000
#当dump .rdb 数据库的时候是否压缩数据对象
rdbcompression yes
#dump 持久化数据保存的文件名
dbfilename dump.rdb
########### Replication #####################
#Redis的主从配置,配置slaveof则实例作为从服务器
#slaveof 192.168.0.105 6379
#主服务器连接密码
# masterauth <master-password>
############## 安全性 ###########
#设置连接密码
#requirepass <password>
############### LIMITS ##############
#最大客户端连接数
# maxclients 128
#最大内存使用率
# maxmemory <bytes>
########## APPEND ONLY MODE #########
#是否开启日志功能
appendonly no
# AOF持久化策略
#appendfsync always
#appendfsync everysec
#appendfsync no
################ VIRTUAL MEMORY ###########
#是否开启VM 功能
#vm-enabled no
# vm-enabled yes
#vm-swap-file logs/redis.swap
#vm-max-memory 0
#vm-page-size 32
#vm-pages 134217728
#vm-max-threads 4
打开你的redis.conf配置文件,示例:
非Windows系统:
sudo vi /etc/redis/redis.confWindows系统:
C:\Intel\Redis\conf\redis.confMaster端redis.conf里注释
bind 127.0.0.1,Slave端才能远程连接到Master端的Redis数据库。daemonize yno表示Redis默认不作为守护进程运行,即在运行redis-server /etc/redis/redis.conf时,将显示Redis启动提示画面;daemonize yes则默认后台运行,不必重新启动新的终端窗口执行其他命令,看个人喜好和实际需要。
三、测试Slave端远程连接Master端
测试中,Master端Windows 10 的IP地址为:192.168.199.108
Master端按指定配置文件启动
redis-server,示例:非Windows系统:
sudo redis-server /etc/redis/redis.confWindows系统:
命令提示符(管理员)模式下执行redis-server C:\Intel\Redis\conf\redis.conf读取默认配置即可。
Master端启动本地
redis-cli:slave端启动
redis-cli -h 192.168.199.108,-h 参数表示连接到指定主机的redis数据库
注意:Slave端无需启动redis-server,Master端启动即可。只要 Slave 端读取到了 Master 端的 Redis 数据库,则表示能够连接成功,可以实施分布式。
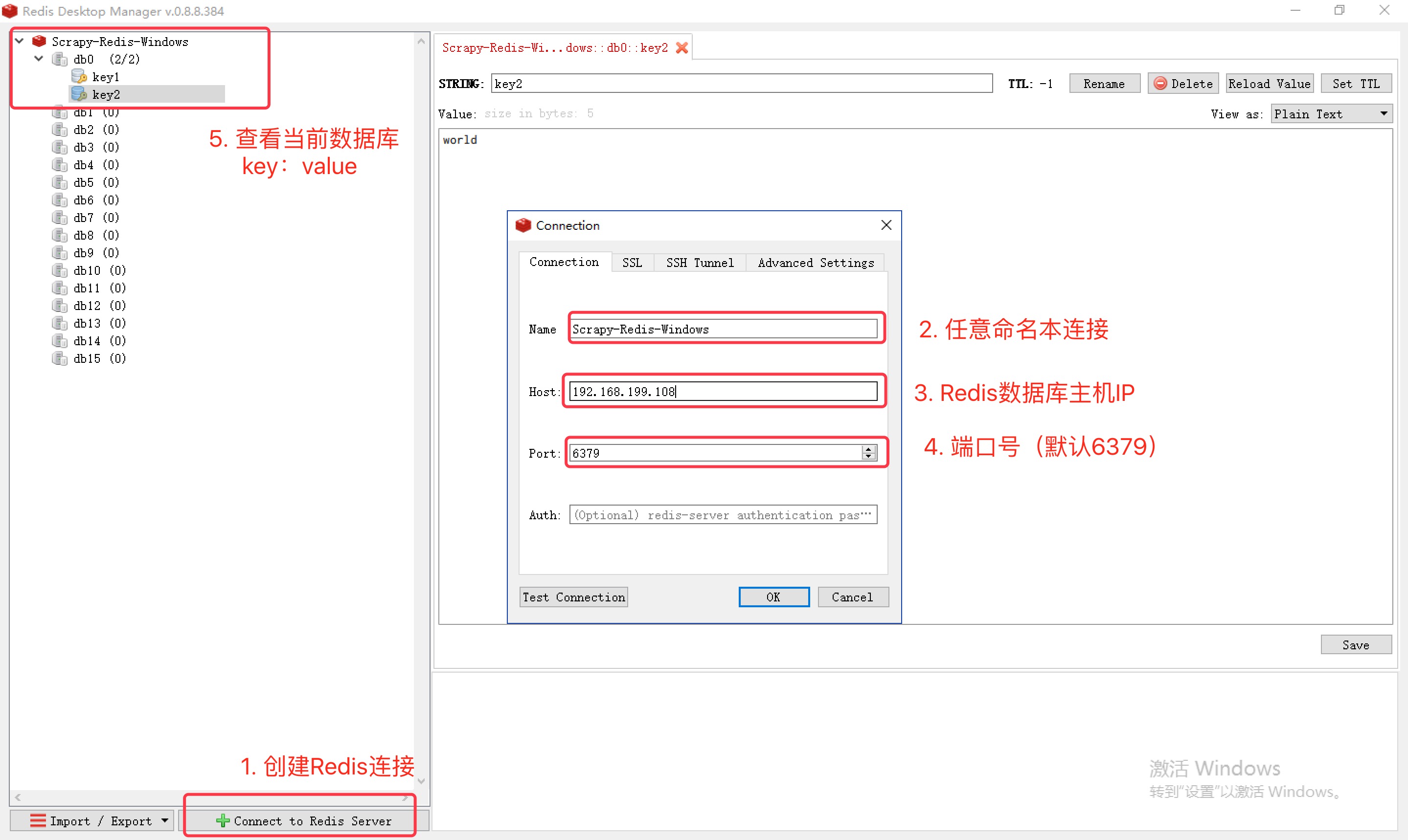
四、Redis数据库桌面管理工具
这里推荐 Redis Desktop Manager,支持 Windows、Mac OS X、Linux 等平台:
五、Redis的数据类型
- 字符串
- 散列/哈希
- 列表
- 集合
- 可排序集合
1.字符串命令
set mykey ''cnblogs'' 创建变量
get mykey 查看变量
getrange mykey start end 获取字符串,如:get name 2 5 #获取name2~5的字符串
strlen mykey 获取长度
incr/decr mykey 加一减一,类型是int
append mykey ''com'' 添加字符串,添加到末尾
2.哈希命令
hset myhash name "cnblogs" 创建变量,myhash类似于变量名,name类似于key,"cnblogs"类似于values
hgetall myhash 得到key和values两者
hget myhash name 得到values
hexists myhash name 检查是否存在这个key
hdel myhash name 删除这个key
hkeys myhash 查看key
hvals muhash 查看values
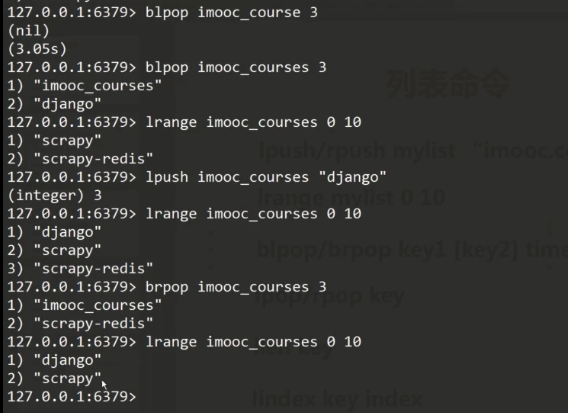
3.列表命令
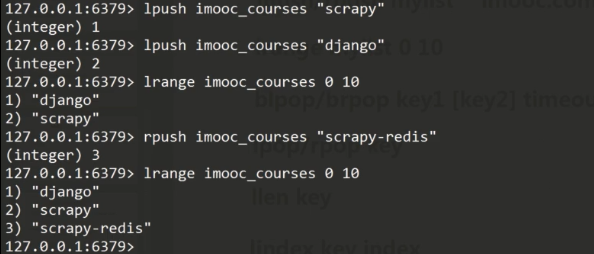
lpush/rpush mylist "cnblogs" 左添加/右添加值
lrange mylist 0 10 查看列表0~10的值
blpop/brpop key1[key2] timeout 左删除/右删除一个,timeout是如果没有key,等待设置的时间后结束。
lpop/rpop key 左删除/右删除,没有等待时间。
llen key 获得长度
lindex key index 取第index元素,index是从0开始的
4.集合命令(不重复)
sadd myset "cnblogs" 添加内容,返回1表示不存在,0表示存在
scard key 查看set中的值
sdiff key1 [key2] 2个set做减法,其实就是减去了交际部分
sinter key1 [key2] 2个set做加法,其实就是留下了两者的交集
spop key 随机删除值
srandmember key member 随机获取member个值
smember key 获取全部的元素
5.可排序集合命令
zadd myset 0 ‘project1’ [1 ‘project2’] 添加集合元素;中括号是没有的,在这里是便于理解
zrangebyscore myset 0 100 选取分数在0~100的元素
zcount key min max 选取分数在min~max的元素的个数