1.网络爬虫
网络爬虫(又被称为网页蜘蛛web spider,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
为什么要做爬虫?
首先请问:都说现在是"大数据时代",那数据从何而来?
政府/机构公开的数据:中华人民共和国国家统计局数据、世界银行公开数据、联合国数据、纳斯达克。爬取网络数据:如果需要的数据市场上没有,或者不愿意购买,那么可以选择招/做一名爬虫工程师,自己动手丰衣足食。拉勾网Python爬虫职位360抢票神器

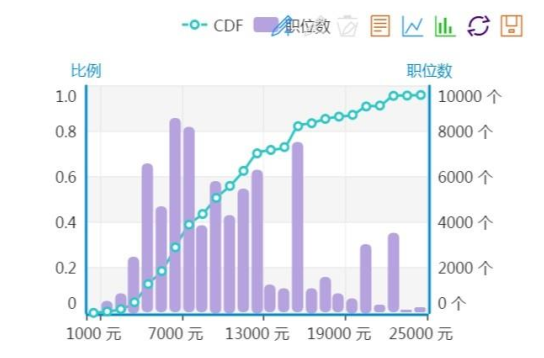
- 月薪分布图
- 云图

2. 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部分组成。控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。解析器的主要工作是下载网页,进行页面的处理,主要是将一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容处理掉,爬虫的基本工作是由解析器完成。资源库是用来存放下载到的网页资源,一般都采用大型的数据库存储,如Oracle数据库,并对其建立索引。
控制器
控制器,它主要是负责根据系统传过来的URL链接,分配一线程,然后启动线程调用爬虫爬取网页的过程。
解析器
解析器是负责网络爬虫的主要部分,其负责的工作主要有:下载网页的功能,对网页的文本进行处理,如过滤功能,抽取特殊HTML标签的功能,分析数据功能。
资源库
主要是用来存储网页中下载下来的数据记录的容器,并提供生成索引的目标源。中大型的数据库产品有:Oracle、Sql Server等。
3.网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列;
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
这个过程就是通过url获取页面,通过页面获取url,就这样回到了哲学问题上,鸡生蛋,蛋生鸡。

4. 抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。我们以下面的图为例:遍历的路径:A-F-G E-H-I B C D
宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接**待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上面的图为例:遍历路径:A-B-C-D-E-F G H I
5、爬虫分类
1.增量型网络爬虫(通用爬虫):与前者相反,没有固定的限制,无休无止直到抓完所有数据。这种类型一般应用于搜索引擎的网站或程序例如谷歌、百度搜索(检索排名PageRank);
2.垂直网络爬虫(聚焦爬虫):聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于:
聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
而我们今后要学习的,就是聚焦爬虫
关于Python爬虫,我们需要学习的有:
1. Python基础语法学习(基础知识)
2. HTML页面的内容抓取(数据抓取)
3. HTML页面的数据提取(数据清洗)
4. Scrapy框架以及scrapy-redis分布式策略(第三方框架)
6. 爬虫(Spider)、反爬虫(Anti-Spider)、反反爬虫(Anti-Anti-Spider)之间的斗争....
6.关心问题
爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
不支持多线程、不支持代理、不能过滤重复URL的,那都不叫开源爬虫,那叫循环执行http请求。能不能爬js生成的信息和爬虫本身没有太大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往需要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往需要耗费很多的时间来处理一个页面。所以一种策略就是,使用这些爬虫来遍历网站,遇到需要解析的页面,就将网页的相关信息提交给模拟浏览器,来完成JS生成信息的抽取。
爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取这些数据有两种方法:使用模拟浏览器(问题1中描述过了),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果是自己生成ajax请求,使用开源爬虫的意义在哪里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。如果我已经可以生成我所需要的ajax请求(列表),如何用这些爬虫来对这些请求进行爬取?爬虫往往都是设计成广度遍历或者深度遍历的模式,去遍历静态或者动态页面。爬取ajax信息属于deep web(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方法来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax请求作为种子,放入爬虫。用爬虫对这些种子,进行深度为1的广度遍历(默认就是广度遍历)。
爬虫怎么爬取要登陆的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登陆主要是靠cookies。至于cookies怎么获取,不是爬虫管的事情。你可以手动获取、用http请求模拟登陆或者用模拟浏览器自动登陆获取cookie。
爬虫怎么抽取网页的信息?
开源爬虫一般都会集成网页抽取工具。主要支持两种规范:CSS SELECTOR和XPATH。至于哪个好,这里不评价。
爬虫怎么保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如scrapy,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加提交数据库的操作。至于使用pipeline这种模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
爬虫被网站封了怎么办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这些开源爬虫一般没有直接支持随机代理的切换。所以用户往往都需要自己将获取的代理,放到一个全局数组中,自己写一个代理随机获取(从数组中)的代码。
网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时怎么用就怎么用,这些爬虫都可以使用。
爬虫速度怎么样?
单机开源爬虫的速度,基本都可以讲本机的网速用到极限。爬虫的速度慢,往往是因为用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速度慢。而这些东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速度,都很可以。
明明代码写对了,爬不到数据,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这种情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
哪个爬虫可以判断网站是否爬完、那个爬虫可以根据主题进行爬取?
爬虫无法判断网站是否爬完,只能尽可能覆盖。至于根据主题爬取,爬虫之后把内容爬下来才知道是什么主题。所以一般都是整个爬下来,然后再去筛选内容。如果嫌爬的太泛,可以通过限制URL正则等方式,来缩小一下范围。
哪个爬虫的设计模式和构架比较好?
设计模式纯属扯淡。说软件设计模式好的,都是软件开发完,然后总结出几个设计模式。设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会使得爬虫的设计更加臃肿。至于构架,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些大家都能控制好。爬虫的业务太简单,谈不上什么构架
7、反爬虫技术
因为搜索引擎的流行,网络爬虫已经成了很普及网络技术,除了专门做搜索的Google,Yahoo,微软,百度以外,几乎每个大型门户网站都有自己的搜索引擎,**小小叫得出来名字得就几十种,还有各种不知名的几千几万种,对于一个内容型驱动的网站来说,受到网络爬虫的光顾是不可避免的。一些智能的搜索引擎爬虫的爬取频率比较合理,对网站资源消耗比较少,但是很多糟糕的网络爬虫,对网页爬取能力很差,经常并发几十上百个请求循环重复抓取,这种爬虫对中小型网站往往是毁灭性打击,特别是一些缺乏爬虫编写经验的程序员写出来的爬虫破坏力极强,造成的网站访问压力会非常大,会导致网站访问速度缓慢,甚至无法访问。一般网站从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫。第三种一些应用ajax的网站会采用,这样增大了爬取的难度。
通过Headers反爬虫
从用户请求的Headers反爬虫是最常见的反爬虫策略。很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
基于用户行为反爬虫
还有一部分网站是通过检测用户行为,例如同一IP短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。